scikit-learn,通常简称为 sklearn,是一个开源的Python库,是基于 Python 编程语言的一个非常流行的机器学习库。它建立在 NumPy 和 SciPy 这两个科学计算库之上,并与 Matplotlib 配合使用,为数据预处理、模型训练、评估和预测提供了一整套解决方案。scikit-learn 是开源的,遵循 BSD 许可证,因此可以自由地在学术和商业项目中使用。
scikit-learn 能做什么?
scikit-learn 包含了广泛的监督学习和无监督学习算法,能够处理分类、回归、聚类、降维、模型选择和预处理任务。具体来说,它可以:
-
数据预处理:包括数据清洗、缺失值处理、特征缩放(如标准化和归一化)、特征编码(如独热编码)等。
-
特征选择和降维:例如 PCA(主成分分析)、LDA(线性判别分析)等方法,帮助减少数据维度,提高模型效率。
-
模型训练:提供多种机器学习算法,如线性回归、逻辑回归、支持向量机、决策树、随机森林、K-近邻、神经网络(虽然相对有限)、集成学习方法等。
-
模型评估:包括交叉验证、混淆矩阵、ROC 曲线、AUC 分数、精确率、召回率、F1 分数等指标,帮助评估模型性能。
-
模型选择与调优:如网格搜索(GridSearchCV)和随机搜索(RandomizedSearchCV),帮助寻找最优模型参数。
-
集成学习:支持投票、Bagging、Boosting 等方法,用于提高模型的稳定性和预测精度。
为什么使用 scikit-learn?
-
简单易用:
scikit-learn的设计注重 API 的一致性,使得用户可以很容易地尝试不同的模型和预处理方法,而无需了解底层的数学细节。 -
高效:它使用 Cython 实现,可以利用多核 CPU 进行并行计算,提高了计算效率。
-
文档完善:拥有详尽的文档和教程,对于初学者和高级用户都非常友好。
-
社区活跃:
scikit-learn拥有庞大的用户和开发者社区,遇到问题时容易获得帮助。 -
兼容性好:与 Python 生态系统中的其他科学计算和数据处理库(如 Pandas、NumPy、Matplotlib)高度兼容,使得数据科学家可以轻松地整合数据预处理、分析、可视化和建模工作流。
以下是一个基本的sklearn教程概览,我们将使用Iris数据集来演示如何进行数据预处理、模型训练和评估:
1. 导入必要的库和数据集
首先,你需要导入sklearn和其他必要的库:
Python
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report2. 加载数据集
使用sklearn内置的数据集加载器来加载数据:
Python
iris = datasets.load_iris()
X = iris.data
y = iris.target3. 数据预处理
将数据分为训练集和测试集,并对数据进行标准化:
Python
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)4. 模型训练
选择一个模型并拟合训练数据:
Python
model = LogisticRegression(max_iter=1000)
model.fit(X_train_std, y_train)5. 预测
使用训练好的模型对测试集进行预测:
Python
y_pred = model.predict(X_test_std)6. 模型评估
评估模型的性能:
Python
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))以上步骤涵盖了使用sklearn的基本流程。当然,实际应用中可能需要更复杂的数据预处理和模型调整,例如特征选择、交叉验证和超参数优化等。此外,sklearn还提供了许多其他类型的模型,如决策树、支持向量机、神经网络等,以及聚类算法和降维技术,如K-Means和PCA。
7. 模型选择与超参数调优
模型的选择和参数调优是机器学习项目中的关键部分。scikit-learn 提供了多种方法来帮助你选择最佳模型和参数组合,例如网格搜索(Grid Search)和随机搜索(Randomized Search)。以下是使用网格搜索的例子:
Python
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100],
'penalty': ['l1', 'l2']}
grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5)
grid_search.fit(X_train_std, y_train)
best_params = grid_search.best_params_
best_score = grid_search.best_score_8. 特征工程
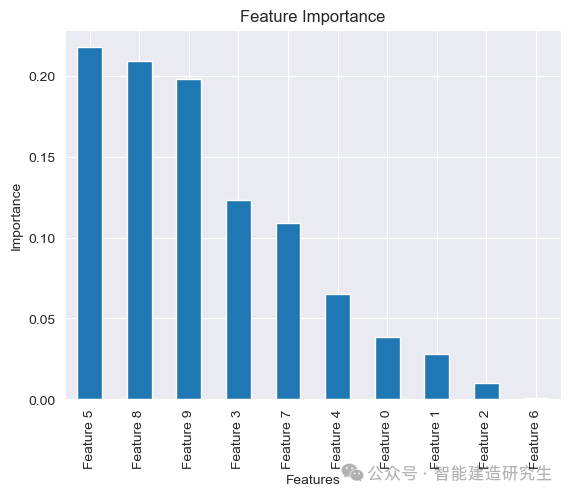
特征工程是指从原始数据中提取和构建有用特征的过程。这可能包括特征选择、特征构造和特征转换。scikit-learn 提供了多种特征工程工具,如特征选择 (SelectKBest) 和主成分分析 (PCA)。
9. 集成学习
集成学习是将多个模型的结果结合起来以提高预测准确性和稳定性的方法。常见的集成学习方法有投票(Voting)、随机森林(Random Forests)和梯度提升(Gradient Boosting)。
10. 交叉验证
交叉验证是一种评估模型泛化能力的方法。它通过将数据分成几个折叠并在每个折叠上轮流训练和测试模型来工作。scikit-learn 中的 cross_val_score 函数可以方便地实现这一点。
11. 管道
管道 (Pipeline) 是一种用于组合多个预处理步骤和模型训练步骤的工具,这样可以简化工作流程并减少代码量。
12. 序列化模型
scikit-learn 支持序列化模型,这意味着你可以将训练好的模型保存到磁盘,然后在以后重新加载并使用它进行预测。这对于部署模型到生产环境非常有用。
13. 可视化
虽然 scikit-learn 不直接提供可视化功能,但可以与 matplotlib, seaborn, plotly 等可视化库结合使用,以帮助理解数据分布和模型表现。
14. 其他算法
scikit-learn 支持广泛的机器学习算法,包括但不限于:
- 分类:支持向量机(SVM)、决策树、K近邻(KNN)、朴素贝叶斯等。
- 回归:岭回归、Lasso回归、弹性网回归、决策树回归等。
- 聚类:K均值、DBSCAN、层次聚类等。
- 降维:PCA、t-SNE、ICA等。







![算法:[动态规划] 斐波那契数列模型](https://i-blog.csdnimg.cn/direct/23e3628609c144098f9e354c3f791af6.png)